#Linux vs Windows
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
### The Benefits of Using Ubuntu Over Microsoft Windows in context of Today's Microsoft Outage
In the ever-evolving world of technology, choosing the right operating system (OS) can significantly impact your productivity, security, and overall user experience. While Microsoft Windows has long been a dominant player in the market, an increasing number of users are turning to Ubuntu for its robust security features and cost-effective solutions. Today, we delve into why Ubuntu is a superior…

View On WordPress
#Free operating system#Free software#Linux vs Windows#Microsoft Windows alternatives#Microsoft Windows outage#Open-source operating system#Switch to Ubuntu#Ubuntu#Ubuntu benefits#Ubuntu cost savings#Ubuntu encryption#Ubuntu firewall#Ubuntu security features#Ubuntu stability#Ubuntu vs Microsoft Windows#Ubuntu vs Windows security
0 notes

Text

The Operating System Vibes (Windows, Mac, and Linux)
Drew this as a cooldown between commissions and courses.
#windows#macos#linux#illustration#art#clip studio paint#pen sketch#sketch to final#sketch vs final#artists on tumblr#silly-fly
9 notes
·
View notes
Text
i have got to learn a different video editing program so i can switch to linux.....
#i have almost all the parts i need to build my new computer but im still hedging on windows vs linux purely because#vegas does NOT work on linux i have looked into it and theres no way#SIGH
4 notes
·
View notes
Text
Trolls vs Vikings: Reborn Game Features and Insights

Trolls vs Vikings: Reborn 2D tower defense strategy game launches now fully tested on Steam Deck and Linux via Windows PC. All thanks to the hard work and dedication of the Megapop team. Which you can find on Steam with a discount. The wait is over! After an epic run in Steam Next Fest and the January Demo Week, Trolls vs Vikings: Reborn is officially out and fully tested on Steam Deck, which also translates to Linux. Whether you're a longtime fan of the original or new to the battlefield, this version brings everything you like. But also cranks it up to legendary status. So, what’s new? Let’s break it down:
Brutal Difficulty – Because You Like the Pain
Think you’re a strategy genius? Try taking on 34 insanely tough new levels that will test every skill you’ve got. Be warned: this mode does not care about your feelings. Trolls vs Vikings: Reborn is designed to make even the most seasoned players second-guess their life choices. If you’re brave enough to embrace the madness, welcome to the challenge.
Special Missions That’ll Twist Your Brain
Packing in 35 new missions featuring Nordic gods, trickster scenarios, and challenges so clever you might feel like you’re earning a Viking PhD. Every mission will push you to think fast, strategize smarter, and, yeah, maybe rage a little.
No More Pay to Win – Just Pure Skill in Trolls vs Vikings: Reborn
Loki tricked Megapop into making the first game free to play. Typical Loki. But they’ve learned their lesson. Now, every upgrade and progression moment is earned through gameplay. No shortcuts. No nonsense. Gameplay is just pure tower defense strategy.
Spells That Hit Different
A reworked spell system, so now every time you unleash one, you’ll feel the power surging through you. It's not just about clicking a button; it's about strategy, timing, and getting that perfect moment to crush the enemy.
Trolls vs Vikings: Reborn - Steam Curators Trailer
youtube
Crisp Visuals & Revamped Vikings
Trolls have never looked this good in high definition. Vikings have been completely reimagined with fresh animations and detailed models. The award-winning animators gave them so much personality, you might actually feel bad stomping them. (Almost.)
Epic Trolls vs Vikings: Reborn Soundtrack – Because Trolls Deserve Bangers
The new Trolls vs Vikings: Reborn theme song “Trolls Forever” by Aleksandar Dimitrijević is a masterpiece. While featuring real troll and gnome musicians. Megapop even went back and remastered the classic tracks. Due to make sure every battle has the perfect soundtrack.
Achievements & Double Speed Mode
Flex your skills with Steam Achievements and show off your tactical prowess. And if you like to live in the fast lane, the entire game can now be played at double speed. Twice the action, twice the chaos, and way less time for second thoughts.
Endless Valhalla Levels – Are You Ready?
The legendary Valhalla mode is back! These endless levels will test your endurance, patience, and sheer willpower. If you think you can survive wave after wave of relentless Viking attacks, this is where you prove it. And here’s the best part — Trolls vs Vikings: Reborn is launching with a 15% discount for its first week! That means you can grab it at a legendary price, just a little under the already sweet $5.99. So, what are you waiting for? Grab your horned helmet, sharpen your tactics, and jump into Trolls vs Vikings: Reborn today. The tower defense strategy battle is calling on Steam for Steam Deck and Linux via Windows PC. Also priced at $5.09 USD / £4.24 / 5,09€ with the 15% discount.
#trolls vs vikings: reborn#tower defense strategy#linux#gaming news#ubuntu#steam deck#windows#pc#unity#Youtube
1 note
·
View note
Video
youtube
Hunt: Showdown [windows vs linux]
0 notes
Text
How I ditched streaming services and learned to love Linux: A step-by-step guide to building your very own personal media streaming server (V2.0: REVISED AND EXPANDED EDITION)
This is a revised, corrected and expanded version of my tutorial on setting up a personal media server that previously appeared on my old blog (donjuan-auxenfers). I expect that that post is still making the rounds (hopefully with my addendum on modifying group share permissions in Ubuntu to circumvent 0x8007003B "Unexpected Network Error" messages in Windows 10/11 when transferring files) but I have no way of checking. Anyway this new revised version of the tutorial corrects one or two small errors I discovered when rereading what I wrote, adds links to all products mentioned and is just more polished generally. I also expanded it a bit, pointing more adventurous users toward programs such as Sonarr/Radarr/Lidarr and Overseerr which can be used for automating user requests and media collection.
So then, what is this tutorial? This is a tutorial on how to build and set up your own personal media server using Ubuntu as an operating system and Plex (or Jellyfin) to not only manage your media, but to also stream that media to your devices both at home and abroad anywhere in the world where you have an internet connection. Its intent is to show you how building a personal media server and stuffing it full of films, TV, and music that you acquired through indiscriminate and voracious media piracy various legal methods will free you to completely ditch paid streaming services. No more will you have to pay for Disney+, Netflix, HBOMAX, Hulu, Amazon Prime, Peacock, CBS All Access, Paramount+, Crave or any other streaming service that is not named Criterion Channel. Instead whenever you want to watch your favourite films and television shows, you’ll have your own personal service that only features things that you want to see, with files that you have control over. And for music fans out there, both Jellyfin and Plex support music streaming, meaning you can even ditch music streaming services. Goodbye Spotify, Youtube Music, Tidal and Apple Music, welcome back unreasonably large MP3 (or FLAC) collections.
On the hardware front, I’m going to offer a few options catered towards different budgets and media library sizes. The cost of getting a media server up and running using this guide will cost you anywhere from $450 CAD/$325 USD at the low end to $1500 CAD/$1100 USD at the high end (it could go higher). My server was priced closer to the higher figure, but I went and got a lot more storage than most people need. If that seems like a little much, consider for a moment, do you have a roommate, a close friend, or a family member who would be willing to chip in a few bucks towards your little project provided they get access? Well that's how I funded my server. It might also be worth thinking about the cost over time, i.e. how much you spend yearly on subscriptions vs. a one time cost of setting up a server. Additionally there's just the joy of being able to scream "fuck you" at all those show cancelling, library deleting, hedge fund vampire CEOs who run the studios through denying them your money. Drive a stake through David Zaslav's heart.
On the software side I will walk you step-by-step through installing Ubuntu as your server's operating system, configuring your storage as a RAIDz array with ZFS, sharing your zpool to Windows with Samba, running a remote connection between your server and your Windows PC, and then a little about started with Plex/Jellyfin. Every terminal command you will need to input will be provided, and I even share a custom #bash script that will make used vs. available drive space on your server display correctly in Windows.
If you have a different preferred flavour of Linux (Arch, Manjaro, Redhat, Fedora, Mint, OpenSUSE, CentOS, Slackware etc. et. al.) and are aching to tell me off for being basic and using Ubuntu, this tutorial is not for you. The sort of person with a preferred Linux distro is the sort of person who can do this sort of thing in their sleep. Also I don't care. This tutorial is intended for the average home computer user. This is also why we’re not using a more exotic home server solution like running everything through Docker Containers and managing it through a dashboard like Homarr or Heimdall. While such solutions are fantastic and can be very easy to maintain once you have it all set up, wrapping your brain around Docker is a whole thing in and of itself. If you do follow this tutorial and had fun putting everything together, then I would encourage you to return in a year’s time, do your research and set up everything with Docker Containers.
Lastly, this is a tutorial aimed at Windows users. Although I was a daily user of OS X for many years (roughly 2008-2023) and I've dabbled quite a bit with various Linux distributions (mostly Ubuntu and Manjaro), my primary OS these days is Windows 11. Many things in this tutorial will still be applicable to Mac users, but others (e.g. setting up shares) you will have to look up for yourself. I doubt it would be difficult to do so.
Nothing in this tutorial will require feats of computing expertise. All you will need is a basic computer literacy (i.e. an understanding of what a filesystem and directory are, and a degree of comfort in the settings menu) and a willingness to learn a thing or two. While this guide may look overwhelming at first glance, it is only because I want to be as thorough as possible. I want you to understand exactly what it is you're doing, I don't want you to just blindly follow steps. If you half-way know what you’re doing, you will be much better prepared if you ever need to troubleshoot.
Honestly, once you have all the hardware ready it shouldn't take more than an afternoon or two to get everything up and running.
(This tutorial is just shy of seven thousand words long so the rest is under the cut.)
Step One: Choosing Your Hardware
Linux is a light weight operating system, depending on the distribution there's close to no bloat. There are recent distributions available at this very moment that will run perfectly fine on a fourteen year old i3 with 4GB of RAM. Moreover, running Plex or Jellyfin isn’t resource intensive in 90% of use cases. All this is to say, we don’t require an expensive or powerful computer. This means that there are several options available: 1) use an old computer you already have sitting around but aren't using 2) buy a used workstation from eBay, or what I believe to be the best option, 3) order an N100 Mini-PC from AliExpress or Amazon.
Note: If you already have an old PC sitting around that you’ve decided to use, fantastic, move on to the next step.
When weighing your options, keep a few things in mind: the number of people you expect to be streaming simultaneously at any one time, the resolution and bitrate of your media library (4k video takes a lot more processing power than 1080p) and most importantly, how many of those clients are going to be transcoding at any one time. Transcoding is what happens when the playback device does not natively support direct playback of the source file. This can happen for a number of reasons, such as the playback device's native resolution being lower than the file's internal resolution, or because the source file was encoded in a video codec unsupported by the playback device.
Ideally we want any transcoding to be performed by hardware. This means we should be looking for a computer with an Intel processor with Quick Sync. Quick Sync is a dedicated core on the CPU die designed specifically for video encoding and decoding. This specialized hardware makes for highly efficient transcoding both in terms of processing overhead and power draw. Without these Quick Sync cores, transcoding must be brute forced through software. This takes up much more of a CPU’s processing power and requires much more energy. But not all Quick Sync cores are created equal and you need to keep this in mind if you've decided either to use an old computer or to shop for a used workstation on eBay
Any Intel processor from second generation Core (Sandy Bridge circa 2011) onward has Quick Sync cores. It's not until 6th gen (Skylake), however, that the cores support the H.265 HEVC codec. Intel’s 10th gen (Comet Lake) processors introduce support for 10bit HEVC and HDR tone mapping. And the recent 12th gen (Alder Lake) processors brought with them hardware AV1 decoding. As an example, while an 8th gen (Kaby Lake) i5-8500 will be able to hardware transcode a H.265 encoded file, it will fall back to software transcoding if given a 10bit H.265 file. If you’ve decided to use that old PC or to look on eBay for an old Dell Optiplex keep this in mind.
Note 1: The price of old workstations varies wildly and fluctuates frequently. If you get lucky and go shopping shortly after a workplace has liquidated a large number of their workstations you can find deals for as low as $100 on a barebones system, but generally an i5-8500 workstation with 16gb RAM will cost you somewhere in the area of $260 CAD/$200 USD.
Note 2: The AMD equivalent to Quick Sync is called Video Core Next, and while it's fine, it's not as efficient and not as mature a technology. It was only introduced with the first generation Ryzen CPUs and it only got decent with their newest CPUs, we want something cheap.
Alternatively you could forgo having to keep track of what generation of CPU is equipped with Quick Sync cores that feature support for which codecs, and just buy an N100 mini-PC. For around the same price or less of a used workstation you can pick up a mini-PC with an Intel N100 processor. The N100 is a four-core processor based on the 12th gen Alder Lake architecture and comes equipped with the latest revision of the Quick Sync cores. These little processors offer astounding hardware transcoding capabilities for their size and power draw. Otherwise they perform equivalent to an i5-6500, which isn't a terrible CPU. A friend of mine uses an N100 machine as a dedicated retro emulation gaming system and it does everything up to 6th generation consoles just fine. The N100 is also a remarkably efficient chip, it sips power. In fact, the difference between running one of these and an old workstation could work out to hundreds of dollars a year in energy bills depending on where you live.
You can find these Mini-PCs all over Amazon or for a little cheaper on AliExpress. They range in price from $170 CAD/$125 USD for a no name N100 with 8GB RAM to $280 CAD/$200 USD for a Beelink S12 Pro with 16GB RAM. The brand doesn't really matter, they're all coming from the same three factories in Shenzen, go for whichever one fits your budget or has features you want. 8GB RAM should be enough, Linux is lightweight and Plex only calls for 2GB RAM. 16GB RAM might result in a slightly snappier experience, especially with ZFS. A 256GB SSD is more than enough for what we need as a boot drive, but going for a bigger drive might allow you to get away with things like creating preview thumbnails for Plex, but it’s up to you and your budget.
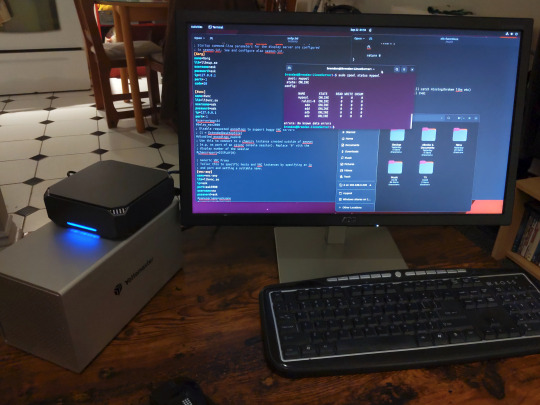
The Mini-PC I wound up buying was a Firebat AK2 Plus with 8GB RAM and a 256GB SSD. It looks like this:

Note: Be forewarned that if you decide to order a Mini-PC from AliExpress, note the type of power adapter it ships with. The mini-PC I bought came with an EU power adapter and I had to supply my own North American power supply. Thankfully this is a minor issue as barrel plug 30W/12V/2.5A power adapters are easy to find and can be had for $10.
Step Two: Choosing Your Storage
Storage is the most important part of our build. It is also the most expensive. Thankfully it’s also the most easily upgrade-able down the line.
For people with a smaller media collection (4TB to 8TB), a more limited budget, or who will only ever have two simultaneous streams running, I would say that the most economical course of action would be to buy a USB 3.0 8TB external HDD. Something like this one from Western Digital or this one from Seagate. One of these external drives will cost you in the area of $200 CAD/$140 USD. Down the line you could add a second external drive or replace it with a multi-drive RAIDz set up such as detailed below.
If a single external drive the path for you, move on to step three.
For people with larger media libraries (12TB+), who prefer media in 4k, or care who about data redundancy, the answer is a RAID array featuring multiple HDDs in an enclosure.
Note: If you are using an old PC or used workstatiom as your server and have the room for at least three 3.5" drives, and as many open SATA ports on your mother board you won't need an enclosure, just install the drives into the case. If your old computer is a laptop or doesn’t have room for more internal drives, then I would suggest an enclosure.
The minimum number of drives needed to run a RAIDz array is three, and seeing as RAIDz is what we will be using, you should be looking for an enclosure with three to five bays. I think that four disks makes for a good compromise for a home server. Regardless of whether you go for a three, four, or five bay enclosure, do be aware that in a RAIDz array the space equivalent of one of the drives will be dedicated to parity at a ratio expressed by the equation 1 − 1/n i.e. in a four bay enclosure equipped with four 12TB drives, if we configured our drives in a RAIDz1 array we would be left with a total of 36TB of usable space (48TB raw size). The reason for why we might sacrifice storage space in such a manner will be explained in the next section.
A four bay enclosure will cost somewhere in the area of $200 CDN/$140 USD. You don't need anything fancy, we don't need anything with hardware RAID controls (RAIDz is done entirely in software) or even USB-C. An enclosure with USB 3.0 will perform perfectly fine. Don’t worry too much about USB speed bottlenecks. A mechanical HDD will be limited by the speed of its mechanism long before before it will be limited by the speed of a USB connection. I've seen decent looking enclosures from TerraMaster, Yottamaster, Mediasonic and Sabrent.
When it comes to selecting the drives, as of this writing, the best value (dollar per gigabyte) are those in the range of 12TB to 20TB. I settled on 12TB drives myself. If 12TB to 20TB drives are out of your budget, go with what you can afford, or look into refurbished drives. I'm not sold on the idea of refurbished drives but many people swear by them.
When shopping for harddrives, search for drives designed specifically for NAS use. Drives designed for NAS use typically have better vibration dampening and are designed to be active 24/7. They will also often make use of CMR (conventional magnetic recording) as opposed to SMR (shingled magnetic recording). This nets them a sizable read/write performance bump over typical desktop drives. Seagate Ironwolf and Toshiba NAS are both well regarded brands when it comes to NAS drives. I would avoid Western Digital Red drives at this time. WD Reds were a go to recommendation up until earlier this year when it was revealed that they feature firmware that will throw up false SMART warnings telling you to replace the drive at the three year mark quite often when there is nothing at all wrong with that drive. It will likely even be good for another six, seven, or more years.

Step Three: Installing Linux
For this step you will need a USB thumbdrive of at least 6GB in capacity, an .ISO of Ubuntu, and a way to make that thumbdrive bootable media.
First download a copy of Ubuntu desktop (for best performance we could download the Server release, but for new Linux users I would recommend against the server release. The server release is strictly command line interface only, and having a GUI is very helpful for most people. Not many people are wholly comfortable doing everything through the command line, I'm certainly not one of them, and I grew up with DOS 6.0. 22.04.3 Jammy Jellyfish is the current Long Term Service release, this is the one to get.
Download the .ISO and then download and install balenaEtcher on your Windows PC. BalenaEtcher is an easy to use program for creating bootable media, you simply insert your thumbdrive, select the .ISO you just downloaded, and it will create a bootable installation media for you.
Once you've made a bootable media and you've got your Mini-PC (or you old PC/used workstation) in front of you, hook it directly into your router with an ethernet cable, and then plug in the HDD enclosure, a monitor, a mouse and a keyboard. Now turn that sucker on and hit whatever key gets you into the BIOS (typically ESC, DEL or F2). If you’re using a Mini-PC check to make sure that the P1 and P2 power limits are set correctly, my N100's P1 limit was set at 10W, a full 20W under the chip's power limit. Also make sure that the RAM is running at the advertised speed. My Mini-PC’s RAM was set at 2333Mhz out of the box when it should have been 3200Mhz. Once you’ve done that, key over to the boot order and place the USB drive first in the boot order. Then save the BIOS settings and restart.
After you restart you’ll be greeted by Ubuntu's installation screen. Installing Ubuntu is really straight forward, select the "minimal" installation option, as we won't need anything on this computer except for a browser (Ubuntu comes preinstalled with Firefox) and Plex Media Server/Jellyfin Media Server. Also remember to delete and reformat that Windows partition! We don't need it.
Step Four: Installing ZFS and Setting Up the RAIDz Array
Note: If you opted for just a single external HDD skip this step and move onto setting up a Samba share.
Once Ubuntu is installed it's time to configure our storage by installing ZFS to build our RAIDz array. ZFS is a "next-gen" file system that is both massively flexible and massively complex. It's capable of snapshot backup, self healing error correction, ZFS pools can be configured with drives operating in a supplemental manner alongside the storage vdev (e.g. fast cache, dedicated secondary intent log, hot swap spares etc.). It's also a file system very amenable to fine tuning. Block and sector size are adjustable to use case and you're afforded the option of different methods of inline compression. If you'd like a very detailed overview and explanation of its various features and tips on tuning a ZFS array check out these articles from Ars Technica. For now we're going to ignore all these features and keep it simple, we're going to pull our drives together into a single vdev running in RAIDz which will be the entirety of our zpool, no fancy cache drive or SLOG.
Open up the terminal and type the following commands:
sudo apt update
then
sudo apt install zfsutils-linux
This will install the ZFS utility. Verify that it's installed with the following command:
zfs --version
Now, it's time to check that the HDDs we have in the enclosure are healthy, running, and recognized. We also want to find out their device IDs and take note of them:
sudo fdisk -1
Note: You might be wondering why some of these commands require "sudo" in front of them while others don't. "Sudo" is short for "super user do”. When and where "sudo" is used has to do with the way permissions are set up in Linux. Only the "root" user has the access level to perform certain tasks in Linux. As a matter of security and safety regular user accounts are kept separate from the "root" user. It's not advised (or even possible) to boot into Linux as "root" with most modern distributions. Instead by using "sudo" our regular user account is temporarily given the power to do otherwise forbidden things. Don't worry about it too much at this stage, but if you want to know more check out this introduction.
If everything is working you should get a list of the various drives detected along with their device IDs which will look like this: /dev/sdc. You can also check the device IDs of the drives by opening the disk utility app. Jot these IDs down as we'll need them for our next step, creating our RAIDz array.
RAIDz is similar to RAID-5 in that instead of striping your data over multiple disks, exchanging redundancy for speed and available space (RAID-0), or mirroring your data writing by two copies of every piece (RAID-1), it instead writes parity blocks across the disks in addition to striping, this provides a balance of speed, redundancy and available space. If a single drive fails, the parity blocks on the working drives can be used to reconstruct the entire array as soon as a replacement drive is added.
Additionally, RAIDz improves over some of the common RAID-5 flaws. It's more resilient and capable of self healing, as it is capable of automatically checking for errors against a checksum. It's more forgiving in this way, and it's likely that you'll be able to detect when a drive is dying well before it fails. A RAIDz array can survive the loss of any one drive.
Note: While RAIDz is indeed resilient, if a second drive fails during the rebuild, you're fucked. Always keep backups of things you can't afford to lose. This tutorial, however, is not about proper data safety.
To create the pool, use the following command:
sudo zpool create "zpoolnamehere" raidz "device IDs of drives we're putting in the pool"
For example, let's creatively name our zpool "mypool". This poil will consist of four drives which have the device IDs: sdb, sdc, sdd, and sde. The resulting command will look like this:
sudo zpool create mypool raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
If as an example you bought five HDDs and decided you wanted more redundancy dedicating two drive to this purpose, we would modify the command to "raidz2" and the command would look something like the following:
sudo zpool create mypool raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
An array configured like this is known as RAIDz2 and is able to survive two disk failures.
Once the zpool has been created, we can check its status with the command:
zpool status
Or more concisely with:
zpool list
The nice thing about ZFS as a file system is that a pool is ready to go immediately after creation. If we were to set up a traditional RAID-5 array using mbam, we'd have to sit through a potentially hours long process of reformatting and partitioning the drives. Instead we're ready to go right out the gates.
The zpool should be automatically mounted to the filesystem after creation, check on that with the following:
df -hT | grep zfs
Note: If your computer ever loses power suddenly, say in event of a power outage, you may have to re-import your pool. In most cases, ZFS will automatically import and mount your pool, but if it doesn’t and you can't see your array, simply open the terminal and type sudo zpool import -a.
By default a zpool is mounted at /"zpoolname". The pool should be under our ownership but let's make sure with the following command:
sudo chown -R "yourlinuxusername" /"zpoolname"
Note: Changing file and folder ownership with "chown" and file and folder permissions with "chmod" are essential commands for much of the admin work in Linux, but we won't be dealing with them extensively in this guide. If you'd like a deeper tutorial and explanation you can check out these two guides: chown and chmod.
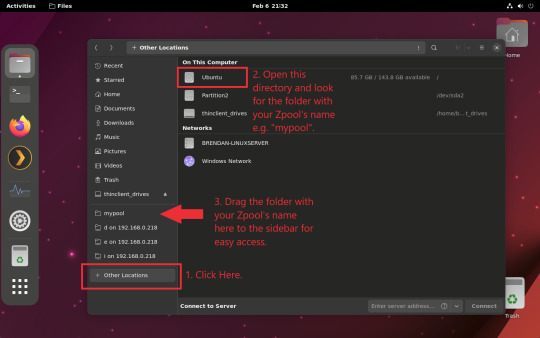
You can access the zpool file system through the GUI by opening the file manager (the Ubuntu default file manager is called Nautilus) and clicking on "Other Locations" on the sidebar, then entering the Ubuntu file system and looking for a folder with your pool's name. Bookmark the folder on the sidebar for easy access.
Your storage pool is now ready to go. Assuming that we already have some files on our Windows PC we want to copy to over, we're going to need to install and configure Samba to make the pool accessible in Windows.
Step Five: Setting Up Samba/Sharing
Samba is what's going to let us share the zpool with Windows and allow us to write to it from our Windows machine. First let's install Samba with the following commands:
sudo apt-get update
then
sudo apt-get install samba
Next create a password for Samba.
sudo smbpswd -a "yourlinuxusername"
It will then prompt you to create a password. Just reuse your Ubuntu user password for simplicity's sake.
Note: if you're using just a single external drive replace the zpool location in the following commands with wherever it is your external drive is mounted, for more information see this guide on mounting an external drive in Ubuntu.
After you've created a password we're going to create a shareable folder in our pool with this command
mkdir /"zpoolname"/"foldername"
Now we're going to open the smb.conf file and make that folder shareable. Enter the following command.
sudo nano /etc/samba/smb.conf
This will open the .conf file in nano, the terminal text editor program. Now at the end of smb.conf add the following entry:
["foldername"]
path = /"zpoolname"/"foldername"
available = yes
valid users = "yourlinuxusername"
read only = no
writable = yes
browseable = yes
guest ok = no
Ensure that there are no line breaks between the lines and that there's a space on both sides of the equals sign. Our next step is to allow Samba traffic through the firewall:
sudo ufw allow samba
Finally restart the Samba service:
sudo systemctl restart smbd
At this point we'll be able to access to the pool, browse its contents, and read and write to it from Windows. But there's one more thing left to do, Windows doesn't natively support the ZFS file systems and will read the used/available/total space in the pool incorrectly. Windows will read available space as total drive space, and all used space as null. This leads to Windows only displaying a dwindling amount of "available" space as the drives are filled. We can fix this! Functionally this doesn't actually matter, we can still write and read to and from the disk, it just makes it difficult to tell at a glance the proportion of used/available space, so this is an optional step but one I recommend (this step is also unnecessary if you're just using a single external drive). What we're going to do is write a little shell script in #bash. Open nano with the terminal with the command:
nano
Now insert the following code:
#!/bin/bash CUR_PATH=`pwd` ZFS_CHECK_OUTPUT=$(zfs get type $CUR_PATH 2>&1 > /dev/null) > /dev/null if [[ $ZFS_CHECK_OUTPUT == *not\ a\ ZFS* ]] then IS_ZFS=false else IS_ZFS=true fi if [[ $IS_ZFS = false ]] then df $CUR_PATH | tail -1 | awk '{print $2" "$4}' else USED=$((`zfs get -o value -Hp used $CUR_PATH` / 1024)) > /dev/null AVAIL=$((`zfs get -o value -Hp available $CUR_PATH` / 1024)) > /dev/null TOTAL=$(($USED+$AVAIL)) > /dev/null echo $TOTAL $AVAIL fi
Save the script as "dfree.sh" to /home/"yourlinuxusername" then change the ownership of the file to make it executable with this command:
sudo chmod 774 dfree.sh
Now open smb.conf with sudo again:
sudo nano /etc/samba/smb.conf
Now add this entry to the top of the configuration file to direct Samba to use the results of our script when Windows asks for a reading on the pool's used/available/total drive space:
[global]
dfree command = /home/"yourlinuxusername"/dfree.sh
Save the changes to smb.conf and then restart Samba again with the terminal:
sudo systemctl restart smbd
Now there’s one more thing we need to do to fully set up the Samba share, and that’s to modify a hidden group permission. In the terminal window type the following command:
usermod -a -G sambashare ��yourlinuxusername”
Then restart samba again:
sudo systemctl restart smbd
If we don’t do this last step, everything will appear to work fine, and you will even be able to see and map the drive from Windows and even begin transferring files, but you'd soon run into a lot of frustration. As every ten minutes or so a file would fail to transfer and you would get a window announcing “0x8007003B Unexpected Network Error”. This window would require your manual input to continue the transfer with the file next in the queue. And at the end it would reattempt to transfer whichever files failed the first time around. 99% of the time they’ll go through that second try, but this is still all a major pain in the ass. Especially if you’ve got a lot of data to transfer or you want to step away from the computer for a while.
It turns out samba can act a little weirdly with the higher read/write speeds of RAIDz arrays and transfers from Windows, and will intermittently crash and restart itself if this group option isn’t changed. Inputting the above command will prevent you from ever seeing that window.
The last thing we're going to do before switching over to our Windows PC is grab the IP address of our Linux machine. Enter the following command:
hostname -I
This will spit out this computer's IP address on the local network (it will look something like 192.168.0.x), write it down. It might be a good idea once you're done here to go into your router settings and reserving that IP for your Linux system in the DHCP settings. Check the manual for your specific model router on how to access its settings, typically it can be accessed by opening a browser and typing http:\\192.168.0.1 in the address bar, but your router may be different.
Okay we’re done with our Linux computer for now. Get on over to your Windows PC, open File Explorer, right click on Network and click "Map network drive". Select Z: as the drive letter (you don't want to map the network drive to a letter you could conceivably be using for other purposes) and enter the IP of your Linux machine and location of the share like so: \\"LINUXCOMPUTERLOCALIPADDRESSGOESHERE"\"zpoolnamegoeshere"\. Windows will then ask you for your username and password, enter the ones you set earlier in Samba and you're good. If you've done everything right it should look something like this:

You can now start moving media over from Windows to the share folder. It's a good idea to have a hard line running to all machines. Moving files over Wi-Fi is going to be tortuously slow, the only thing that’s going to make the transfer time tolerable (hours instead of days) is a solid wired connection between both machines and your router.
Step Six: Setting Up Remote Desktop Access to Your Server
After the server is up and going, you’ll want to be able to access it remotely from Windows. Barring serious maintenance/updates, this is how you'll access it most of the time. On your Linux system open the terminal and enter:
sudo apt install xrdp
Then:
sudo systemctl enable xrdp
Once it's finished installing, open “Settings” on the sidebar and turn off "automatic login" in the User category. Then log out of your account. Attempting to remotely connect to your Linux computer while you’re logged in will result in a black screen!
Now get back on your Windows PC, open search and look for "RDP". A program called "Remote Desktop Connection" should pop up, open this program as an administrator by right-clicking and selecting “run as an administrator”. You’ll be greeted with a window. In the field marked “Computer” type in the IP address of your Linux computer. Press connect and you'll be greeted with a new window and prompt asking for your username and password. Enter your Ubuntu username and password here.
If everything went right, you’ll be logged into your Linux computer. If the performance is sluggish, adjust the display options. Lowering the resolution and colour depth do a lot to make the interface feel snappier.
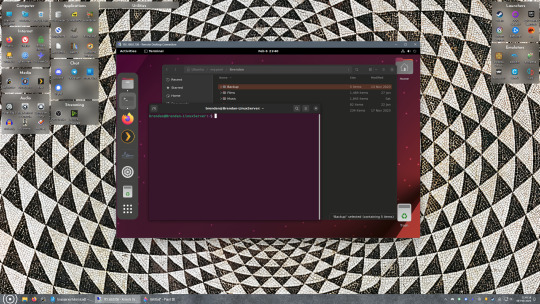
Remote access is how we're going to be using our Linux system from now, barring edge cases like needing to get into the BIOS or upgrading to a new version of Ubuntu. Everything else from performing maintenance like a monthly zpool scrub to checking zpool status and updating software can all be done remotely.

This is how my server lives its life now, happily humming and chirping away on the floor next to the couch in a corner of the living room.
Step Seven: Plex Media Server/Jellyfin
Okay we’ve got all the ground work finished and our server is almost up and running. We’ve got Ubuntu up and running, our storage array is primed, we’ve set up remote connections and sharing, and maybe we’ve moved over some of favourite movies and TV shows.
Now we need to decide on the media server software to use which will stream our media to us and organize our library. For most people I’d recommend Plex. It just works 99% of the time. That said, Jellyfin has a lot to recommend it by too, even if it is rougher around the edges. Some people run both simultaneously, it’s not that big of an extra strain. I do recommend doing a little bit of your own research into the features each platform offers, but as a quick run down, consider some of the following points:
Plex is closed source and is funded through PlexPass purchases while Jellyfin is open source and entirely user driven. This means a number of things: for one, Plex requires you to purchase a “PlexPass” (purchased as a one time lifetime fee $159.99 CDN/$120 USD or paid for on a monthly or yearly subscription basis) in order to access to certain features, like hardware transcoding (and we want hardware transcoding) or automated intro/credits detection and skipping, Jellyfin offers some of these features for free through plugins. Plex supports a lot more devices than Jellyfin and updates more frequently. That said, Jellyfin's Android and iOS apps are completely free, while the Plex Android and iOS apps must be activated for a one time cost of $6 CDN/$5 USD. But that $6 fee gets you a mobile app that is much more functional and features a unified UI across platforms, the Plex mobile apps are simply a more polished experience. The Jellyfin apps are a bit of a mess and the iOS and Android versions are very different from each other.
Jellyfin’s actual media player is more fully featured than Plex's, but on the other hand Jellyfin's UI, library customization and automatic media tagging really pale in comparison to Plex. Streaming your music library is free through both Jellyfin and Plex, but Plex offers the PlexAmp app for dedicated music streaming which boasts a number of fantastic features, unfortunately some of those fantastic features require a PlexPass. If your internet is down, Jellyfin can still do local streaming, while Plex can fail to play files unless you've got it set up a certain way. Jellyfin has a slew of neat niche features like support for Comic Book libraries with the .cbz/.cbt file types, but then Plex offers some free ad-supported TV and films, they even have a free channel that plays nothing but Classic Doctor Who.
Ultimately it's up to you, I settled on Plex because although some features are pay-walled, it just works. It's more reliable and easier to use, and a one-time fee is much easier to swallow than a subscription. I had a pretty easy time getting my boomer parents and tech illiterate brother introduced to and using Plex and I don't know if I would've had as easy a time doing that with Jellyfin. I do also need to mention that Jellyfin does take a little extra bit of tinkering to get going in Ubuntu, you’ll have to set up process permissions, so if you're more tolerant to tinkering, Jellyfin might be up your alley and I’ll trust that you can follow their installation and configuration guide. For everyone else, I recommend Plex.
So pick your poison: Plex or Jellyfin.
Note: The easiest way to download and install either of these packages in Ubuntu is through Snap Store.
After you've installed one (or both), opening either app will launch a browser window into the browser version of the app allowing you to set all the options server side.
The process of adding creating media libraries is essentially the same in both Plex and Jellyfin. You create a separate libraries for Television, Movies, and Music and add the folders which contain the respective types of media to their respective libraries. The only difficult or time consuming aspect is ensuring that your files and folders follow the appropriate naming conventions:
Plex naming guide for Movies
Plex naming guide for Television
Jellyfin follows the same naming rules but I find their media scanner to be a lot less accurate and forgiving than Plex. Once you've selected the folders to be scanned the service will scan your files, tagging everything and adding metadata. Although I find do find Plex more accurate, it can still erroneously tag some things and you might have to manually clean up some tags in a large library. (When I initially created my library it tagged the 1963-1989 Doctor Who as some Korean soap opera and I needed to manually select the correct match after which everything was tagged normally.) It can also be a bit testy with anime (especially OVAs) be sure to check TVDB to ensure that you have your files and folders structured and named correctly. If something is not showing up at all, double check the name.
Once that's done, organizing and customizing your library is easy. You can set up collections, grouping items together to fit a theme or collect together all the entries in a franchise. You can make playlists, and add custom artwork to entries. It's fun setting up collections with posters to match, there are even several websites dedicated to help you do this like PosterDB. As an example, below are two collections in my library, one collecting all the entries in a franchise, the other follows a theme.

My Star Trek collection, featuring all eleven television series, and thirteen films.
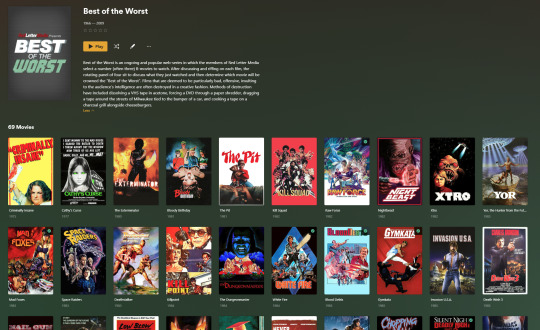
My Best of the Worst collection, featuring sixty-nine films previously showcased on RedLetterMedia’s Best of the Worst. They’re all absolutely terrible and I love them.
As for settings, ensure you've got Remote Access going, it should work automatically and be sure to set your upload speed after running a speed test. In the library settings set the database cache to 2000MB to ensure a snappier and more responsive browsing experience, and then check that playback quality is set to original/maximum. If you’re severely bandwidth limited on your upload and have remote users, you might want to limit the remote stream bitrate to something more reasonable, just as a note of comparison Netflix’s 1080p bitrate is approximately 5Mbps, although almost anyone watching through a chromium based browser is streaming at 720p and 3mbps. Other than that you should be good to go. For actually playing your files, there's a Plex app for just about every platform imaginable. I mostly watch television and films on my laptop using the Windows Plex app, but I also use the Android app which can broadcast to the chromecast connected to the TV in the office and the Android TV app for our smart TV. Both are fully functional and easy to navigate, and I can also attest to the OS X version being equally functional.
Part Eight: Finding Media
Now, this is not really a piracy tutorial, there are plenty of those out there. But if you’re unaware, BitTorrent is free and pretty easy to use, just pick a client (qBittorrent is the best) and go find some public trackers to peruse. Just know now that all the best trackers are private and invite only, and that they can be exceptionally difficult to get into. I’m already on a few, and even then, some of the best ones are wholly out of my reach.
If you decide to take the left hand path and turn to Usenet you’ll have to pay. First you’ll need to sign up with a provider like Newshosting or EasyNews for access to Usenet itself, and then to actually find anything you’re going to need to sign up with an indexer like NZBGeek or NZBFinder. There are dozens of indexers, and many people cross post between them, but for more obscure media it’s worth checking multiple. You’ll also need a binary downloader like SABnzbd. That caveat aside, Usenet is faster, bigger, older, less traceable than BitTorrent, and altogether slicker. I honestly prefer it, and I'm kicking myself for taking this long to start using it because I was scared off by the price. I’ve found so many things on Usenet that I had sought in vain elsewhere for years, like a 2010 Italian film about a massacre perpetrated by the SS that played the festival circuit but never received a home media release; some absolute hero uploaded a rip of a festival screener DVD to Usenet. Anyway, figure out the rest of this shit on your own and remember to use protection, get yourself behind a VPN, use a SOCKS5 proxy with your BitTorrent client, etc.
On the legal side of things, if you’re around my age, you (or your family) probably have a big pile of DVDs and Blu-Rays sitting around unwatched and half forgotten. Why not do a bit of amateur media preservation, rip them and upload them to your server for easier access? (Your tools for this are going to be Handbrake to do the ripping and AnyDVD to break any encryption.) I went to the trouble of ripping all my SCTV DVDs (five box sets worth) because none of it is on streaming nor could it be found on any pirate source I tried. I’m glad I did, forty years on it’s still one of the funniest shows to ever be on TV.
Part Nine/Epilogue: Sonarr/Radarr/Lidarr and Overseerr
There are a lot of ways to automate your server for better functionality or to add features you and other users might find useful. Sonarr, Radarr, and Lidarr are a part of a suite of “Servarr” services (there’s also Readarr for books and Whisparr for adult content) that allow you to automate the collection of new episodes of TV shows (Sonarr), new movie releases (Radarr) and music releases (Lidarr). They hook in to your BitTorrent client or Usenet binary newsgroup downloader and crawl your preferred Torrent trackers and Usenet indexers, alerting you to new releases and automatically grabbing them. You can also use these services to manually search for new media, and even replace/upgrade your existing media with better quality uploads. They’re really a little tricky to set up on a bare metal Ubuntu install (ideally you should be running them in Docker Containers), and I won’t be providing a step by step on installing and running them, I’m simply making you aware of their existence.
The other bit of kit I want to make you aware of is Overseerr which is a program that scans your Plex media library and will serve recommendations based on what you like. It also allows you and your users to request specific media. It can even be integrated with Sonarr/Radarr/Lidarr so that fulfilling those requests is fully automated.
And you're done. It really wasn't all that hard. Enjoy your media. Enjoy the control you have over that media. And be safe in the knowledge that no hedgefund CEO motherfucker who hates the movies but who is somehow in control of a major studio will be able to disappear anything in your library as a tax write-off.
1K notes
·
View notes
Text
The biggest reason I haven't tried Linux is accessibility. To run NVDA (my screen-reader that I love dearly) on Linux, I have to also run Windows on a Virtual Machine, and that would seem to defeat the purpose of switching to Linux in the first place. I don't know of any screen-reader in Linux that's as rich in features and has a synth I can tolerate. But I might just be behind the times.
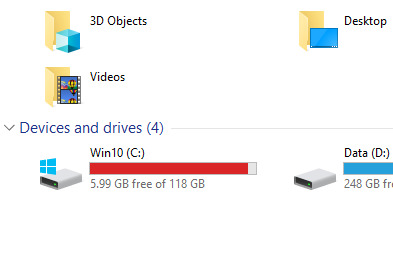
Oh I'm sorry C: you've only got 6GB free? Only six fucking gig? We used to boot the OS off fucking floppy drives but I'm so so sorry that six entire gigabytes of free space isn't enough for you you poor starving thing. You've been experiencing worse and worse memory issues for months and now you're freezing and crashing every few minutes because why, you just can't make 6 gig work? Grow the fuck up.
#Windows vs. Linux#Also I'm used to Windows and dunno where to find all the things I'd need to run all the stuff I'd want to run on there#Including games I like that are Windows-specific#Aside from aforementioned Bootcamp solution#Which again defeats the purpose of having Linux because you have Windows AS WELL#And all the problems that entails
5K notes
·
View notes
Text

Welcome back, coding enthusiasts! Today we'll talk about Git & Github , the must-know duo for any modern developer. Whether you're just starting out or need a refresher, this guide will walk you through everything from setup to intermediate-level use. Let’s jump in!
What is Git?
Git is a version control system. It helps you as a developer:
Track changes in your codebase, so if anything breaks, you can go back to a previous version. (Trust me, this happens more often than you’d think!)
Collaborate with others : whether you're working on a team project or contributing to an open-source repo, Git helps manage multiple versions of a project.
In short, Git allows you to work smarter, not harder. Developers who aren't familiar with the basics of Git? Let’s just say they’re missing a key tool in their toolkit.
What is Github ?
GitHub is a web-based platform that uses Git for version control and collaboration. It provides an interface to manage your repositories, track bugs, request new features, and much more. Think of it as a place where your Git repositories live, and where real teamwork happens. You can collaborate, share your code, and contribute to other projects, all while keeping everything well-organized.
Git & Github : not the same thing !
Git is the tool you use to create repositories and manage code on your local machine while GitHub is the platform where you host those repositories and collaborate with others. You can also host Git repositories on other platforms like GitLab and BitBucket, but GitHub is the most popular.
Installing Git (Windows, Linux, and macOS Users)
You can go ahead and download Git for your platform from (git-scm.com)
Using Git
You can use Git either through the command line (Terminal) or through a GUI. However, as a developer, it’s highly recommended to learn the terminal approach. Why? Because it’s more efficient, and understanding the commands will give you a better grasp of how Git works under the hood.
GitWorkflow
Git operates in several key areas:
Working directory (on your local machine)
Staging area (where changes are prepared to be committed)
Local repository (stored in the hidden .git directory in your project)
Remote repository (the version of the project stored on GitHub or other hosting platforms)
Let’s look at the basic commands that move code between these areas:
git init: Initializes a Git repository in your project directory, creating the .git folder.
git add: Adds your files to the staging area, where they’re prepared for committing.
git commit: Commits your staged files to your local repository.
git log: Shows the history of commits.
git push: Pushes your changes to the remote repository (like GitHub).
git pull: Pulls changes from the remote repository into your working directory.
git clone: Clones a remote repository to your local machine, maintaining the connection to the remote repo.
Branching and merging
When working in a team, it’s important to never mess up the main branch (often called master or main). This is the core of your project, and it's essential to keep it stable.
To do this, we branch out for new features or bug fixes. This way, you can make changes without affecting the main project until you’re ready to merge. Only merge your work back into the main branch once you're confident that it’s ready to go.
Getting Started: From Installation to Intermediate
Now, let’s go step-by-step through the process of using Git and GitHub from installation to pushing your first project.
Configuring Git
After installing Git, you’ll need to tell Git your name and email. This helps Git keep track of who made each change. To do this, run:

Master vs. Main Branch
By default, Git used to name the default branch master, but GitHub switched it to main for inclusivity reasons. To avoid confusion, check your default branch:

Pushing Changes to GitHub
Let’s go through an example of pushing your changes to GitHub.
First, initialize Git in your project directory:

Then to get the ‘untracked files’ , the files that we haven’t added yet to our staging area , we run the command

Now that you’ve guessed it we’re gonna run the git add command , you can add your files individually by running git add name or all at once like I did here

And finally it's time to commit our file to the local repository

Now, create a new repository on GitHub (it’s easy , just follow these instructions along with me)
Assuming you already created your github account you’ll go to this link and change username by your actual username : https://github.com/username?tab=repositories , then follow these instructions :


You can add a name and choose wether you repo can be public or private for now and forget about everything else for now.

Once your repository created on github , you’ll get this :

As you might’ve noticed, we’ve already run all these commands , all what’s left for us to do is to push our files from our local repository to our remote repository , so let’s go ahead and do that

And just like this we have successfully pushed our files to the remote repository
Here, you can see the default branch main, the total number of branches, your latest commit message along with how long ago it was made, and the number of commits you've made on that branch.

Now what is a Readme file ?
A README file is a markdown file where you can add any relevant information about your code or the specific functionality in a particular branch—since each branch can have its own README.
It also serves as a guide for anyone who clones your repository, showing them exactly how to use it.
You can add a README from this button:

Or, you can create it using a command and push it manually:

But for the sake of demonstrating how to pull content from a remote repository, we’re going with the first option:

Once that’s done, it gets added to the repository just like any other file—with a commit message and timestamp.
However, the README file isn’t on my local machine yet, so I’ll run the git pull command:

Now everything is up to date. And this is just the tiniest example of how you can pull content from your remote repository.
What is .gitignore file ?
Sometimes, you don’t want to push everything to GitHub—especially sensitive files like environment variables or API keys. These shouldn’t be shared publicly. In fact, GitHub might even send you a warning email if you do:

To avoid this, you should create a .gitignore file, like this:

Any file listed in .gitignore will not be pushed to GitHub. So you’re all set!
Cloning
When you want to copy a GitHub repository to your local machine (aka "clone" it), you have two main options:
Clone using HTTPS: This is the most straightforward method. You just copy the HTTPS link from GitHub and run:

It's simple, doesn’t require extra setup, and works well for most users. But each time you push or pull, GitHub may ask for your username and password (or personal access token if you've enabled 2FA).
But if you wanna clone using ssh , you’ll need to know a bit more about ssh keys , so let’s talk about that.
Clone using SSH (Secure Shell): This method uses SSH keys for authentication. Once set up, it’s more secure and doesn't prompt you for credentials every time. Here's how it works:
So what is an SSH key, actually?
Think of SSH keys as a digital handshake between your computer and GitHub.
Your computer generates a key pair:
A private key (stored safely on your machine)
A public key (shared with GitHub)
When you try to access GitHub via SSH, GitHub checks if the public key you've registered matches the private key on your machine.
If they match, you're in — no password prompts needed.
Steps to set up SSH with GitHub:
Generate your SSH key:

2. Start the SSH agent and add your key:

3. Copy your public key:

Then copy the output to your clipboard.
Add it to your GitHub account:
Go to GitHub → Settings → SSH and GPG keys
Click New SSH key
Paste your public key and save.
5. Now you'll be able to clone using SSH like this:

From now on, any interaction with GitHub over SSH will just work — no password typing, just smooth encrypted magic.
And there you have it ! Until next time — happy coding, and may your merges always be conflict-free! ✨👩💻👨💻
#code#codeblr#css#html#javascript#java development company#python#studyblr#progblr#programming#comp sci#web design#web developers#web development#website design#webdev#website#tech#html css#learn to code#github
93 notes
·
View notes
Text
Linux distros - what is the difference, which one should I choose?
Caution, VERY long post.
With more and more simmers looking into linux lately, I've been seeing the same questions over and over again: Which distro should I choose? Is distro xyz newbie-friendly? Does this program work on that distro?
So I thought I'd explain the concept of "distros" and clear some of that up.
What are the key differences between distros?
Linux distros are NOT different operating systems (they're all still linux!) and the differences between them aren't actually as big as you think.
Update philosophy: Some distros, like Ubuntu, (supposedly) focus more on stability than being up-to-date. These distros will release one big update once every year or every other year and they are thoroughly tested. However, because the updates are so huge, they inevitably tend to break stuff anyway. On the other end of the spectrum are so-called "rolling release" distros like Arch. They don't do big annual updates, but instead release smaller updates very frequently. They are what's called "bleeding edge" - if there is something new out there, they will be the first ones to get it. This can of course impact stability, but on the other hand, stuff gets improved and fixed very fast. Third, there are also "middle of the road" distros like Fedora, which kind of do... both. Fedora gets big version updates like Ubuntu, but they happen more frequently and are comparably smaller, thus being both stable and reasonably up-to-date.
Package manager: Different distros come with different package managers (APT on ubuntu, DNF on Fedora, etc.). Package managers keep track of all the installed programs on your PC and allow you to update/install/remove programs. You'll often work with the package manager in the terminal: For example, if you want to install lutris on Fedora, you'd type in "sudo dnf install lutris" ("sudo" stands for "super user do", it's the equivalent of administrator rights on Windows). Different package managers come with different pros and cons.
Core utilities and programs: 99% of distros use the same stuff in the background (you don’t even directly interact with it, e.g. background process managing). The 1% that do NOT use the same stuff are obscure distros like VoidLinux, Artix, Alpine, Gentoo, Devuan. If you are not a Linux expert, AVOID THOSE AT ALL COST.
Installation process: Some distros are easier to install than others. Arch is infamous for being a bit difficult to install, but at the same time, its documentation is unparalleled. If you have patience and good reading comprehension, installing arch would literally teach you all you ever need to know about Linux. If you want to go an easier and safer route for now, anything with an installer like Mint or Fedora would suit you better.
Community: Pick a distro with an active community and lots of good documentation! You’ll need help. If you are looking at derivatives (e.g. ZorinOS, which is based on Ubuntu which is based on Debian), ask yourself: Does this derivative give you enough benefits to potentially give up community support of the larger distro it is based on? Usually, the answer is no.
Okay, but what EDITION of this distro should I choose?
"Editions" or “spins” usually refer to variations of the same distro with different desktop environments. The three most common ones you should know are GNOME, KDE Plasma and Cinnamon.
GNOME's UI is more similar to MacOS, but not exactly the same.
KDE Plasma looks and feels a lot like Windows' UI, but with more customization options.
Cinnamon is also pretty windows-y, but more restricted in terms of customization and generally deemed to be "stuck in 2010".
Mint vs. Pop!_OS vs. Fedora
Currently, the most popular distros within the Sims community seem to be Mint and Fedora (and Pop!_OS to some extent). They are praised for being "beginner friendly". So what's the difference between them?
Both Mint and Pop!_OS are based on Ubuntu, whereas Fedora is a "standalone" upstream distro, meaning it is not based on another distro.
Personally, I recommend Fedora over Mint and Pop!_OS for several reasons. To name only a few:
I mentioned above that Ubuntu's update philosophy tends to break things once a big update rolls around every two years. Since both Mint and Pop!_OS are based on Ubuntu, they are also affected by this.
Ubuntu, Mint and Pop!_OS like to modify their stuff regularly for theming/branding purposes, but this ALSO tends to break things. It is apparently so bad that there is an initiative to stop this.
Pop!_OS uses the GNOME desktop environment, which I would not recommend if you are switching from Windows. Mint offers Cinnamon, which is visually and technically outdated (they use the x11 windowing system standard from 1984), but still beloved by a lot of people. Fedora offers the more modern KDE Plasma.
Personal observation: Most simmers I've encountered who had severe issues with setting up Linux went with an Ubuntu-based distro. There's just something about it that's fucked up, man.
And this doesn't even get into the whole Snaps vs. Flatpak controvery, but I will skip this for brevity.
Does SimPE (or any other program) work on this distro?
If it works on Fedora, then it works on Mint/Ubuntu/Arch/etc., and vice versa. This is all just a question of having the necessary dependencies installed and installing the program itself properly. Some distros may have certain prerequisites pre-installed, while others don't, but you can always just install those yourself. Like I said, different distros are NOT different operating systems. It's all still Linux and you can ultimately customize it however you want.
In short: Yeah, all Sims 2-related programs work. Yes, ReShade too. It ultimately doesn't really matter what distro you use as long as it is not part of the obscure 1% I mentioned above.
A little piece of advice
Whatever distro you end up choosing: get used to googling stuff and practice reading comprehension! There are numerous forums, discord servers and subreddits where you can ask people for help. Generally speaking, the linux community is very open to helping newbies. HOWEVER, they are not as tolerant to nagging and laziness as the Sims community tends to be. Show initiative, use google search & common sense, try things out before screaming for help and be detailed and respectful when explaining your problems. They appreciate that. Also, use the arch wiki even if you do not use Arch Linux – most of it is applicable to other distros as well.
#simming on linux#bnb.txt#if anyone wants to use this as a base for a video feel free#i don't feel like like recording and editing lol
119 notes
·
View notes
Text
may i present:
Residence: ETERNITY
a Red vs. Blue dating sim
in this short and unserious dating sim, make choices as Church to date any of the original Blood Gulch crew. there are 10 different endings (A-J) to get!
available for free on itch.io here:
#residence: eternity because hes stuck there. in blood gulch. forever. also because im amused by how serious it sounds#took a bit because. i kept forgetting to post it. oops.#rvb#reddin and bluein#R:E#theta thoughts#church
92 notes
·
View notes
Text
If you're a linux[1] user who deploys multiple devices, I implore you: learn the command `scp`. It will change your life
It lets you copy files over an ssh pipe; if there's an ssh server on that host, you can essentially directly address a known file on that filesystem and say pwease gimme. And it's roughly the same syntax as `cp`, just with a `[user]@[host]:` before *either source or destination*[2].
And the real kicker is that neither source nor destination need be local:
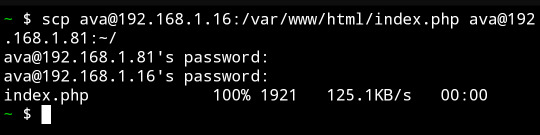
I copied a file from my web server to an icecast source client host by passing it through my phone.
Unreasonably handy tool to have on your toolbelt.
Footnotes under the cut.
[1] Okay, fine, you got me! It's not solely a linux util. SCP is part of the openssh suite, which means that it's available on virtually every OS under the sun... Including being included by default on Windows 10 1709 and later versions of Windows. It's already on your mac, your BSD system, and almost certainly your phone, too. SSH servers and *nix go together like picnics and baskets, though, so I wouldn't exactly pull the *average* windows user aside to recc' `scp`.
[2] What's most interesting to me is that the `[user]@[host]` is used for the SSH client to know where it's authenticating and how, but the actual filesystem location's format is not processed by the SSH client; it's the *server's* format, not the client, that matters for parsing the file location. In some cases this can lead to a mismatch on filenames that you're receiving vs requesting, but the -T flag disables that checking, and then use `[email protected]:D:\\Documents\\testdata.bin` (drive letter indicated and backslashes escaped) to refer to it
#openssh#scp#linux#i am sorry to secure contain protect fans who are uninterested in this being in your tags but. hash collisons happen
147 notes
·
View notes
Text
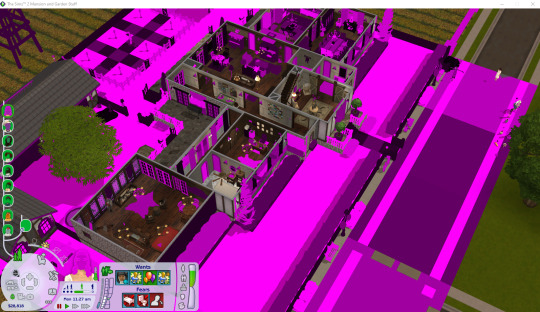

Windows vs. Linux... Just sayin...
#sims 2#oceanside sims#bacc#lot tour#ts2#new oceanside#goodacre#goodacre's farm#sims 2 on linux#sims 2 on windows
33 notes
·
View notes
Note
Eka, do you have any beginner tips for learning Linux? Or recommendations? 🪡
hello mysterious sewing needle anon! I'm not sure what the "beginner" distro is these days, maybe Mint?
in no particular order:
definitely make sure you have a "backup" machine.
get comfortable using a terminal. you'll want to do this sooner or later. if you have a command called foobar, "man foobar" and "foobar --help" (that's two hyphens) will generally show you help.
fish is a good shell, imo more newbie friendly than sh or bash or zsh or whatever.
get comfortable with your distribution's package manager of choice, and prefer installing stuff from it if you can. it's a vastly better experience than windows's "download random shit and let it install itself".
for other things, flatpak is a reasonable alternative.
if you're editing config files by hand, make a backup copy of them. there are some fancy tools for managing config files but I'm not aware of any that are beginner-friendly.
if you fuck up your system so bad you can't get a graphical environment, you can use ctrl-alt-f2 to switch to a virtual terminal
if you fuck it up so bad you can't even boot, you can boot off a USB stick, mount your hard drive, and fix it that way. the installer you use for your distro will work for this.
when it comes to desktop environments, I have no particular opinions on gnome vs plasma vs. whatever else is out there because I use sway because I'm cool. anything that describes itself as being based on "Wayland" is newer, and some things might not work as well (screensharing), but will have better support for HiDPI displays
many Steam games that are not officially supported on Linux can be made to run anyway, and will run just as well. I don't remember the setting for this. for non-Steam games, not sure.
overall, have fun! it has its quirks but I'm happy knowing that my computer isn't going to try to force telemetry and AI nonsense onto me
65 notes
·
View notes
Text
Gods vs Horrors Demo Launching for Steam Next Fest

Gods vs Horrors demo for the roguelike card auto-battler game is coming to Linux, Steam Deck, and Windows PC. All thanks to the creative genius of Oriol Cosp Game. Working to make its way onto Steam soon. The battle between divine might and cosmic nightmares is about to heat up. Gods vs Horrors demo, the roguelike card auto-battler game where legendary Gods team up to fight off eldritch terrors, is getting a huge update — just in time for Steam Next Fest (Feb 24 – Mar 3, 2025). But here’s the catch: this special update is only available on Linux during the event, so don’t miss out.
What’s New in the Gods vs Horrors Demo?
This update cranks up the action with new content, fresh mechanics, and even more strategic depth for players who love crafting the perfect divine battle plan. Here’s what’s coming:
A New Boss – Arachnomir This eldritch spider isn’t just creepy — it’s deadly. Arachnomir summons waves of enemies, keeping the pressure on while you scramble to build the right lineup.
A Brand-New Mythology to Unlock The Gods vs Horrors roster is expanding from 5 to 6 mythologies for the demo. Meaning more Gods, more combos, and more wild strategies to experiment with.
The Blessings Mechanic Strategic buffs at key moments? Yes, please! This new system gives powerful boosts during your run, forcing you to decide when and how to best use them.
Controller Support Steam Deck users, rejoice! Now you can take your divine war on the go or play with a controller for a more relaxed experience.
Gods vs Horrors - UI update trailer for the demo
youtube
Why You Should Try This Demo
Since it first dropped, the Gods vs Horrors demo has been hooking players with its deep build variety and intense battles. It’s not just a quick playthrough—players are averaging over 5 hours of gameplay, with a median session time of 1 hour and 7 minutes. That’s pretty wild for a demo!If you’re into roguelike card deckbuilders and auto-battler gamess, this one’s got everything: recruit legendary Gods, upgrade their powers, tweak your battlefield formations, and test out epic build synergies as you battle against the horrors of the unknown.
Mark Your Calendar!
The updated demo releases on February 24, right before Steam Next Fest kicks off. If you haven’t already, Wishlist Gods vs Horrors on Steam so you don’t miss out on the new demo. Who knows what other surprises the devs have in store?The Gods are calling—will you answer? Check it out on Linux, Steam Deck, or Windows PC, and get ready for the fight of a lifetime.
#gods vs horrors#demo#roguelike card#auto-battler#linux#gaming news#oriol cosp games#ubuntu#steam deck#windows#pc#unity#Youtube
0 notes
Text
Yuri VN/Game Tourney S2: Semifinals
Bad End Theater vs Blue Reflection: Second Light


Info and propaganda under the cut! Not guaranteed to be spoiler-free
BAD END THEATER
Description/Propaganda:
through the bulk of the game, you play as four protagonists in a basic fantasy setting, and the choices you make as each protagonist affect what happens to all the others when you switch perspectives. of note for this tournament are the maiden and the overlord who fall in love (the overlord is a girl!) but destiny seems to only tear them apart, as this is BAD END THEATER and there's seemingly nothing but bad endings in store for them.
(major spoilers beyond this point!)
once you get everyone's "true ending", you have the opportunity to jump into the story and save the four yourself, which causes the theatre's owner, TRAGEDY, to challenge you to a fight. once you win, everyone gets their happy ending. but what about TRAGEDY...? well, if you collected every single bad ending in the game, you have a chance at the very end to meet up with TRAGEDY. she tells you how she fell in love with a girl, but society tore them apart. she based the maiden off of herself, and the overlord after her girlfriend. she opened the theater hoping to find her lost love, as TRAGEDY always loved to write sad stories, and her girlfriend would give them happy endings. just as she thinks there's no hope left for her, YOU reveal yourself to be her girlfriend after all, and she gets her happy ending, too.
Content Warnings/Other Info: violence and blood (in a cartoony pixel art style). Available for $9.99 USD on itch.io, GOG, Steam, Google Play, and Humblebundle (Windows, Mac, Linux, Android)
Blue Reflection: Second Light
Description/Propaganda:
A rare non-VN game/RPG with yuri at its centre! Blue Reflection Second Light is a magical girl RPG made by Gust (the Atelier company), and is the sequel to Blue Reflection, but can be played on its own. While its predecessor was mainly yuri bait, the second game has explicitly sapphic relationships in it.
The main character, Ao, finds herself awakening in a mysterious school surrounded by endless ocean, with only herself and three other girls inside it. The four of them build a new life for themselves inside the school while trying to recover their lost memories. The game is full of yuri hints. The girls live and work together in the school, and in their free time, go on "dates," which range from fully platonic to very romantic. Ao has ship teases with many of the girls, most of all the villain-turned hero, Uta. Additionally, you get a special ending with whichever girl you spend the most time with.
While the whole game feels yuri-esque, what makes it explicitly a yuri game is the revelation that two of the girls, before they lost their memories, were in love with each other. Their story before they lost their memories ended tragically, but now, they have a second chance to be in a romantic relationship with each other. Their relationship is cute and heartfelt, and it was such a pleasant surprise to hear them say "I'm in love with you" explicitly.
Blue Reflection: Second Light is a heartfelt, cozy, and exciting game deeply focused on the relationships between girls, whether platonic, romantic, or somewhere in between. It's fun to play, has beautiful art and music, and wonderful relationships. Please give it a try and consider voting for it!
Content Warnings/Other Info:
referenced self harm, death, and animal cruelty referenced terminal illness
available on Switch and Steam (Windows) for $59.99 USD
27 notes
·
View notes